3.3 Autoévaluation
Les données peuvent être retrouvées dans le dossier Module 3.
Question 1
a. Quelle est la différence entre une expérience et une étude d’observation?
Réponse
L’expérience implique l’assignation aléatoire des traitements aux unités expérimentales et on contrôle toutes les variables, en faisant varier uniquement les variables pour lesquelles on veut tester l’effet. Une étude d’observation implique une sélection aléatoire des unités expérimentales, mais les traitements ne sont pas appliqués aléatoirement (ils ont été appliqués par quelqu’un d’autre).
Par exemple, si on s’intéresse à la vitalité des petits commerces dans les villes où des commerces de grande surface se sont installés, on peut sélectionner aléatoirement les villes qui seront prises en compte dans l’étude. Toutefois, la présence ou non d’un commerce de grande surface n’a pas été attribuée aléatoirement. De plus, on n’a aucun contrôle sur plusieurs variables dans l’étude d’observation (p. ex., population de la ville, nombre de petits commerces, distances entre les commerces).
b. Quel est le terme utilisé pour désigner la probabilité de rejeter correctement une hypothèse nulle qui devrait être rejetée lors d’une analyse statistique?
Réponse
C’est la puissance statistique dont il est question ici.c. L’erreur de type I est la probabilité de rejeter par erreur une hypothèse nulle qui est vraie. Vrai ou faux?
Réponse
Vraid. Donnez trois moyens pour augmenter la puissance statistique d’une analyse.
Réponse
Augmenter la taille d’échantillon, réduire la variabilité (en définissant mieux la population statistique d’intérêt) et augmenter le seuil \(\alpha\) sont tous des moyens qui permettent d’augmenter la puissance d’une analyse statistique.e. Donnez deux suppositions du test \(t\) sur un seul groupe.
Réponse
La normalité des résidus et l’indépendance des observations sont les deux principales suppositions à vérifier. La troisième supposition, c’est-à-dire que la moyenne provient d’une distribution normale de moyennes, est un produit dérivé du théorème de la limite centrale.Question 2
a. Importez le jeu de données temp.csv. Ce dernier contient les données sur la température de l’air pour différentes stations de mesures météorologiques (Site) dans l’Arctique. La colonne Diff.temp est le résultat de la différence entre la température maximale de 2010 et celle de 1950.
Réponse
##importer fichier
temp <- read.table(file = "Module_3/data/temp.csv", header = TRUE)
## ou
temp <- read.table(file = "Module_3/data/temp.csv", header = TRUE, sep=",")
##on regarde les premières lignes du jeu de données
head(temp)## Site Diff.temp
## 1 site1 2.991231
## 2 site2 5.526125
## 3 site3 4.684332
## 4 site4 8.547139
## 5 site5 5.467885
## 6 site6 6.274520b. On émet l’hypothèse scientifique que le réchauffement climatique a augmenté les températures maximales dans l’Arctique. Émettez des hypothèses statistiques qui permettent de tester l’hypothèse scientifique et spécifiez un seuil de signification (\(\alpha\)).
Réponse
Puisqu’on émet une hypothèse à l’effet que la température maximale était plus grande en 2010 qu’en 1950, nous nous attendrons à ce que la variable Diff.temp (température maximale 2010 - température maximale 1950) prenne des valeurs positives. Nous avons donc les hypothèses statistiques suivantes :
\(H_a\): \(\mu > 0\) (la moyenne est supérieure à 0)
On fixe le seuil de signification, au choix, \(\alpha = 0.05\)
c. Effectuez un test d’hypothèse à l’aide du test \(t\).
Réponse
d. Vérifiez les suppositions du test. Utilisez un test formel et une méthode graphique informelle pour vérifier la normalité.
Réponse
##on calcule les résidus
res <- temp$Diff.temp - mean(temp$Diff.temp)
##si ce package n'est pas installé, on l'installe
##avec install.packages( )
##une fois installé, on peut charger le package
##on charge le package nortest
library(nortest)
ad.test(res)##
## Anderson-Darling normality test
##
## data: res
## A = 0.31088, p-value = 0.5438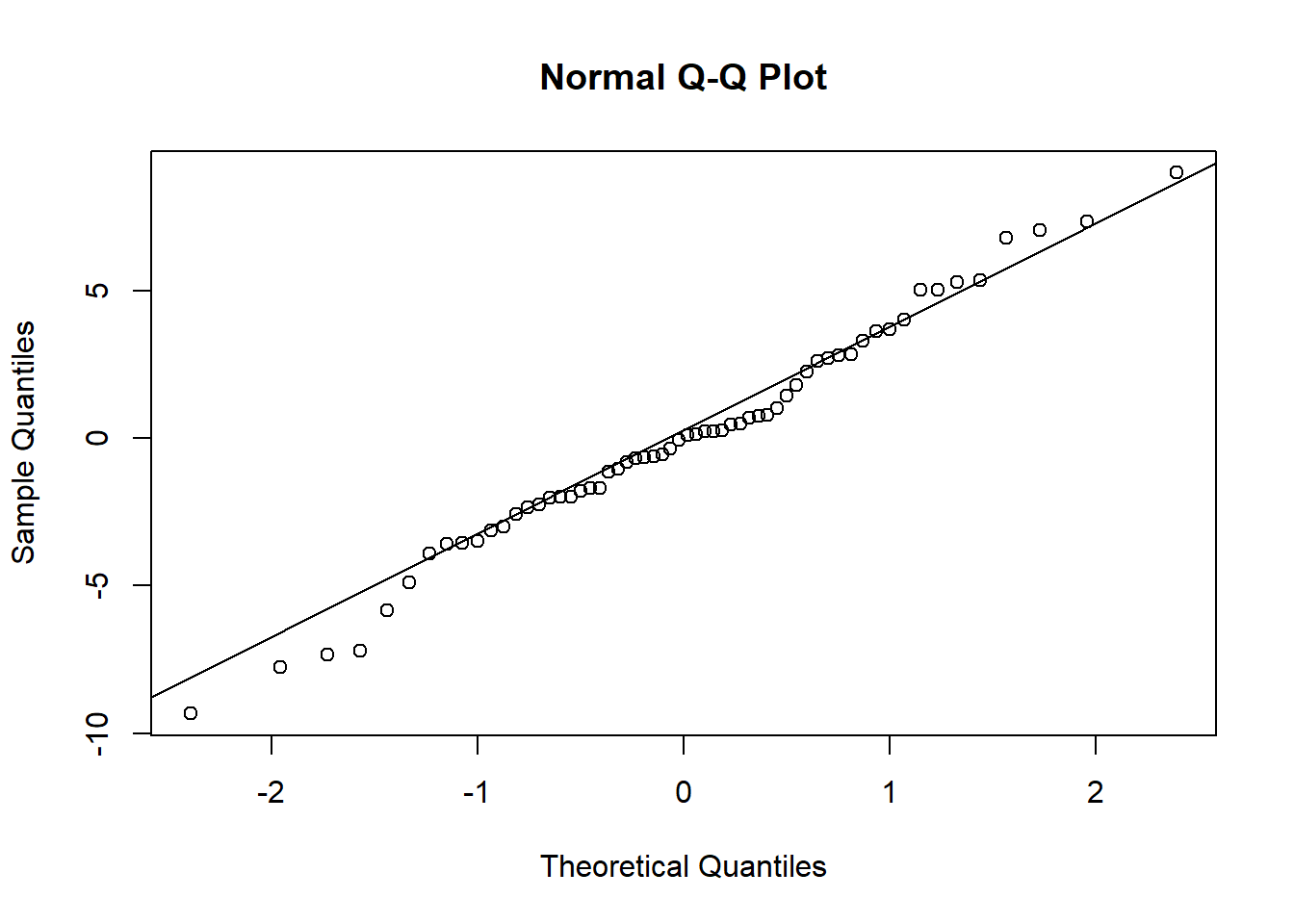
e. Interprétez les résultats de l’analyse à la lumière de l’hypothèse scientifique.
Réponse
##
## One Sample t-test
##
## data: temp$Diff.temp
## t = 10.627, df = 59, p-value = 1.256e-15
## alternative hypothesis: true mean is greater than 0
## 95 percent confidence interval:
## 4.418407 Inf
## sample estimates:
## mean of x
## 5.242877