6.1 Leçon
6.1.1 Comparaison de plusieurs groupes
Nous avons vu que le test \(t\) permet de comparer deux groupes afin de déterminer s’ils proviennent de la même population. Dans certains cas, on s’intéresse à plus de deux groupes. Par exemple, on pourrait vouloir comparer la distance quotidienne parcourue par les chauffeurs de trois compagnies de transport différentes. Rappelons qu’à chaque fois que nous réalisons un test d’hypothèse statistique, nous avons une probabilité \(\alpha\) de commettre une erreur de type I (c.-à-d., déclarer une différence lorsqu’il n’y en a pas, un faux positif). Avec trois groupes (A, B, C), il existe trois comparaisons possibles:
\[ A \: vs \: B \qquad A \: vs \: C \qquad B \: vs \: C\]
À noter que la comparaison \(A \: vs \: B\) est identique à \(B \: vs \: A\). La probabilité de trouver une différence entre les trois moyennes est supérieure à \(\alpha\). Plus on fait de comparaisons avec un test \(t\) (e.g., \(A \: vs \: B\), \(A \: vs \: C\)), plus on risque de conclure à tort qu’il y a une différence entre les moyennes des groupes (c.-à-d. l’erreur de type I augmente avec le nombre de comparaisons). Si les tests sont indépendants, on peut calculer la probabilité de commettre au moins une erreur de type I à l’aide de l’équation:
\[P = 1 - (1 - \alpha)^k\]
où \(\alpha\) est le seuil de signification pour chaque comparaison et \(k\) est le nombre de comparaisons effectuées. Pour un seuil fixé à \(\alpha = 0.05\) :
- avec 3 comparaisons, la probabilité de commettre une erreur de type I est de 0.14;
- avec 10 comparaisons, la probabilité de commettre une erreur de type I est de 0.40;
- avec 20 comparaisons, la probabilité de commettre une erreur de type I est de 0.64.
Toutefois, si les comparaisons ne sont pas indépendantes, la probabilité réelle de commettre une erreur de type I est inférieure ou égale à celle obtenue avec l’équation ci-haut. On comprend que l’augmentation du nombre de comparaisons risque d’entraîner des conclusions erronées.
Une alternative à ce problème consiste à corriger le seuil \(\alpha\) par le nombre de comparaisons que l’on veut effectuer. C’est ce qu’on appelle l’ajustement de Bonferroni (Bonferroni adjustment).
Dans une expérience où on étudie 5 traitements différents, nous avons cinq moyennes arithmétiques (5 groupes: A, B, C, D, E) et les comparaisons suivantes :
\[\begin{align*} & A \: \text{vs} \: B \\ & A \: \text{vs} \: C \quad \text{and} \quad B \: \text{vs} \: C \\ & A \: \text{vs} \: D \quad \text{and} \quad B \: \text{vs} \: D \quad \text{and} \quad C \: \text{vs} \: D \\ & A \: \text{vs} \: E \quad \text{and} \quad B \: \text{vs} \: E \quad \text{and} \quad C \: \text{vs} \: E \quad \text{and} \quad D \: \text{vs} \: E \: . \end{align*}\]
Puisqu’il y a 10 comparaisons, on devrait diviser le seuil \(\alpha\) par 10 pour exécuter l’ajustement de Bonferroni. Si on utilise un seuil de 0.05, il faudra observer \(P \leq 0.005\) pour déclarer une différence significative entre deux groupes (\(\alpha/10 = 0.05/10 = 0.005\)).
On constate que l’ajustement de Bonferroni est une stratégie souvent trop conservatrice, qui augmente la probabilité de commettre une erreur de type II (un faux négatif). Une meilleure stratégie consiste à comparer tous les groupes simultanément. C’est d’ailleurs ce que permet de faire l’analyse de variance – on compare tous les groupes en une seule étape.
6.1.2 Analyse de variance (ANOVA)
L’analyse de variance (analysis of variance, ANOVA) est une approche statistique qui compare les moyennes de plusieurs groupes entre eux pour déterminer si au moins un des groupes diffère des autres. Le scénario typique de l’ANOVA est celui d’une expérience visant à comparer l’effet d’une variable catégorique sur une variable réponse d’intérêt. Une variable catégorique est une variable à partir de laquelle la variable réponse peut être classée dans une catégorie particulière. Par variable réponse, on entend une variable dépendante que l’on mesure et qui peut être influencée par la variable catégorique. On utilise aussi le terme facteur pour désigner une variable catégorique. En fait, les termes “variable catégorique”, “facteur” et “critère” sont souvent interchangeables dans la littérature. Nous utiliserons le terme “facteur” pour les besoins du cours.
Des exemples de variables catégoriques incluent les classes d’âge (jeune, mature, vieux), les traitements pharmaceutiques (médicament 1, médicament 2, placebo), et la concentration d’engrais (très faible, modérée, élevée, très élevée). Dans le contexte de l’ANOVA, la variable réponse est une variable numérique continue qui varie selon les niveaux du facteur. Comme nous le verrons plus loin, l’ANOVA est l’extension du test \(t\) pour des cas avec des variables catégoriques qui ont plus de 2 niveaux.
Étant donné que l’on s’intéresse aux moyennes, on pourrait se demander pourquoi appeler cette approche ANOVA. Lorsqu’on réalise une ANOVA, on détermine si la variabilité des données expliquée par le traitement est plus grande que la variabilité inexpliquée. Pour ce faire, nous calculons la somme des carrés (sum of squares). Le concept de la somme des carrés a été présenté lors de la leçon 1 Statistiques descriptives.
6.1.2.1 Décomposition de la variance
6.1.2.1.1 Sommes des carrés
Pendant l’ANOVA, on décortique la variance totale des données en différentes composantes: une partie expliquée et une autre inexpliquée. Puisque les sommes des carrés sont additives, on peut écrire :
\[SST = SSA + SSE \: \] où \(SST\) correspond à la somme des carrés totale, \(SSA\) correspond à la somme des carrés du facteur \(A\) (aussi appelée somme des carrés du traitement) et \(SSE\) est la somme des carrés des erreurs. On peut diviser les sommes des carrés par les degrés de liberté appropriés pour obtenir le carré moyen (la variance) attribuable aux effets qui nous intéressent. Nous présentons dans les prochaines lignes le calcul de chacune des sommes des carrés discutées précédemment.
On calcule la somme des carrés totale (\(SST\)):
\[ SST = \sum_{i=1}^n (y_i - \bar{y})^2\]
où \(y_i\) est la \(i^{\mathrm{i\grave{e}me}}\) observation et \(\bar{y}\) représente la moyenne globale de toutes les observations (tous les groupes confondus). Cette somme des carrés compare chaque observation à la moyenne globale. Les degrés de liberté associés à \(SST\) sont obtenus avec \(df = N - 1\), où \(N\) correspond au nombre total d’observations.
On calcule la somme des carrés des erreurs (\(SSE\)):
\[ SSE = \sum_{j=1}^k \sum_{i=1}^n (y_{ij} - \bar{y_j})^2\]
où \(y_{ij}\) correspond à la \(i^{\mathrm{i\grave{e}me}}\) observation du groupe \(j\) et \(\bar{y_j}\) est la moyenne du groupe \(j\). Cette somme des carrés compare chaque observation à la moyenne de son groupe respectif. On obtient les degrés de liberté avec \(df = k(n - 1)\), où \(k\) correspond au nombre de groupes et \(n\) correspond au nombre d’observations dans chacun des groupes.
On calcule la somme des carrés du facteur \(A\) (le traitement qui définit les différents groupes) (\(SSA\)):
\[SSA = \sum_{j=1}^k \sum_{i=1}^n (\bar{y}_{j} - \bar{y})^2 = n \sum_{j=1}^k (\bar{y}_{j} - \bar{y})^2\] où \(\bar{y}_{j}\) correspond à la moyenne du groupe \(j\), \(\bar{y}\) est la moyenne globale et \(n\) correspond au nombre d’observations dans chacun des groupes. On peut aussi la calculer par soustraction à l’aide de \(SSA = SST - SSE\). La somme des carrés du traitement compare la moyenne de chaque groupe à la moyenne globale. Les degrés de liberté s’obtiennent avec \(df = k - 1\) où \(k\) est le nombre de groupes dans le facteur \(A\).
On veut déterminer si la concentration d’ozone en parties par million (ppm) diffère entre trois jardins d’une ville industrielle. Le jeu de données jardins.txt contient les observations suivantes :
##importation du jeu de données
ozone <- read.table("Module_6/data/jardins.txt", header = TRUE)
ozone## Ozone Jardin
## 1 14.82 A
## 2 20.59 A
## 3 6.18 A
## 4 7.61 A
## 5 31.35 A
## 6 11.62 A
## 7 32.70 A
## 8 26.18 A
## 9 19.91 A
## 10 10.96 A
## 11 12.60 A
## 12 17.09 A
## 13 5.97 A
## 14 17.95 A
## 15 9.60 A
## 16 20.46 B
## 17 18.26 B
## 18 28.63 B
## 19 14.81 B
## 20 14.22 B
## 21 13.97 B
## 22 20.19 B
## 23 16.21 B
## 24 23.63 B
## 25 21.02 B
## 26 20.41 B
## 27 18.59 B
## 28 13.19 B
## 29 18.28 B
## 30 11.15 B
## 31 10.03 C
## 32 11.58 C
## 33 26.68 C
## 34 5.61 C
## 35 12.21 C
## 36 24.87 C
## 37 18.60 C
## 38 34.78 C
## 39 14.63 C
## 40 17.09 C
## 41 5.05 C
## 42 20.53 C
## 43 28.67 C
## 44 12.19 C
## 45 28.65 COn peut visualiser les données à l’aide d’un diagramme de boîtes et moustaches (Figure 6.1).
##diagramme de boîtes et moustaches
boxplot(Ozone ~ Jardin, data = ozone,
ylab = "Concentration d'ozone (ppm)",
xlab = "Jardin", cex.lab = 1.2)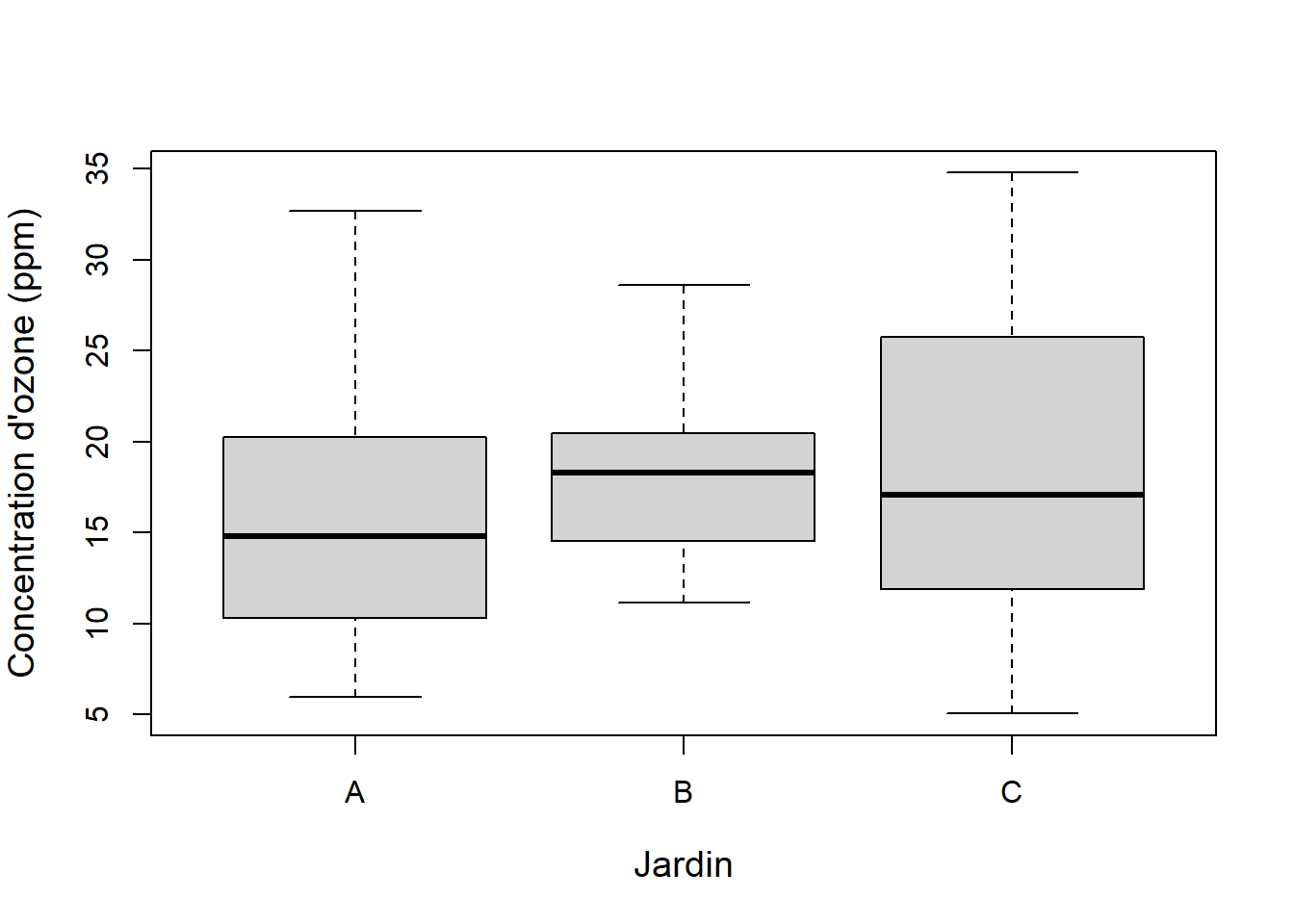
Figure 6.1: Diagramme de boîtes et moustaches de la concentration d’ozone dans les trois jardins.
La somme des carrés des erreurs s’obtient ainsi :
\[ SSE = \hspace{1em} \sum_{j=1}^k \sum_{i=1}^n (y_{ij} - \bar{y_j})^2 \hspace{2em} \bar{y_A} = 16.34 \hspace{2em} \bar{y_B} = 18.20 \hspace{2em} \bar{y_C} = 18.08 \] \[ SSE = \hspace{1em}\sum_{i=1}^n((y_{iA} - \bar{y_A})^2 + (y_{iB} - \bar{y_B})^2 + (y_{iC} - \bar{y_C})^2) \]
\[ SSE = (14.82 - 16.34)^2 + \ldots + (9.60 - 16.34)^2 + \]
\[\hspace{1em} (20.46 - 18.20)^2 + \ldots + (11.15 - 18.20)^2 + \]
\[\hspace{1em} (10.03 - 18.08)^2 + \ldots + (28.65 - 18.08)^2 \]
\[ SSE = 2451.5 \]
On calcule la somme des carrés des traitements avec l’équation complète ou par soustraction:
\[ SSA = \sum_{j=1}^k \sum_{i=1}^n (\bar{y}_{j} - \bar{y})^2 = n \sum_{j=1}^k (\bar{y}_{j} - \bar{y})^2 \hspace{4em} n_A = n_B = n_C = 15 \]
\[SSA = 15 \cdot ((16.34 - 17.54)^2 + (18.20 - 17.54)^2 + (18.08 - 17.54)^2) \]
\[SSA = 32.43\]
On effectue ces calculs dans R :
## [1] 2483.881## [1] 44##SSE
##sous-jeu de données
ozoneA <- ozone[ozone$Jardin == "A", ]
ozoneB <- ozone[ozone$Jardin == "B", ]
ozoneC <- ozone[ozone$Jardin == "C", ]
##SSE de A
SSE.A <- sum((ozoneA$Ozone-mean(ozoneA$Ozone))^2)
##SSE de B
SSE.B <- sum((ozoneB$Ozone-mean(ozoneB$Ozone))^2)
##SSE de C
SSE.C <- sum((ozoneC$Ozone-mean(ozoneC$Ozone))^2)
SSE <- SSE.A + SSE.B + SSE.C
SSE## [1] 2451.451## [1] 42## [1] 32.43014##autre façon de la calculer
SSA.alt <- (15 * (mean(ozoneA$Ozone) - mean(ozone$Ozone))^2) +
(15 * (mean(ozoneB$Ozone) - mean(ozone$Ozone))^2) +
(15 * (mean(ozoneC$Ozone) - mean(ozone$Ozone))^2)
SSA.alt## [1] 32.43014## [1] 26.1.2.1.2 Tableau de l’ANOVA
Après avoir calculé les sommes des carrés des différents termes ainsi que leurs degrés de liberté respectifs, on peut les assembler dans un tableau d’ANOVA (Table 6.1). Ce tableau constitue une partie importante des résultats de l’analyse et doit figurer dans les rapports ou au moins y être résumé par écrit.
| Source | Somme des carrés (\(SS\)) | Degrés de liberté (\(df\)) | Carré moyen (\(CM\)) | ratio \(F\) |
|---|---|---|---|---|
| Traitement | \(SSA\) | \(k-1\) | \(SSA/df_A\) | \(MSA/MSE\) |
| Erreur | \(SSE\) | \(k(n-1)\) | \(SSE/df_{erreur}\) | |
| Total | \(SST\) | \(N-1\) |
Le carré moyen du traitement (\(SSA/df_A\)) estime la variance due au traitement, alors que le carré moyen des erreurs (\(SSE/df_{erreur}\)) estime la variance inexpliquée aussi appelée variance résiduelle (residual variance). La variance résiduelle est la meilleure estimation de la variance (\(\sigma^2\)) commune à tous les \(k\) groupes comparés. C’est une des raisons pour lesquelles la méthode est appelée “analyse de variance” : on estime en même temps la variance commune à tous les groupes.
Le ratio \(F\) consiste à comparer la variabilité expliquée et la variabilité inexpliquée. Si le ratio est nettement supérieur à 1, c’est parce que la variance expliquée par le traitement excède de beaucoup la variance résiduelle: il y a probablement un effet du traitement sur la variable réponse. Un ratio inférieur ou s’approchant de 1 suggère qu’il n’y a pas d’effet du traitement. L’interprétation du ratio \(F\) dépend aussi de la taille de l’échantillon. Ce ratio de variances est comparé à une distribution théorique, celle du \(F\).
6.1.2.2 La distribution du \(F\)
La distribution du \(F\) est une distribution continue qui est définie par la fonction de densité :
\[ f(x \vert \nu_1, \nu_2) = \frac{\sqrt{\frac{(\nu_1 x)^{\nu_1}\nu_{2}^{\nu_2}}{(\nu_1 x + \nu_2)^{\nu_1 + \nu_2}}}}{x \mathrm{B} \left (\frac{\nu_1}{2}, \frac{\nu_2}{2} \right )} \: \]
où \(\nu_1\) et \(\nu_2\) sont les degrés de liberté et \(B\) est la fonction beta qui implique des intégrales (voir ?beta dans R). En ce qui concerne l’application de cette distribution à l’ANOVA, les degrés de liberté \(\nu_1\) et \(\nu_2\) sont ceux associés au numérateur et au dénominateur du ratio \(F\), respectivement, c.-à-d., \(df_A\) et \(df_{erreur}\) tels que présentés dans le Tableau 6.1. La Figure 6.2 présente la forme de la distribution du \(F\) selon différents degrés de liberté. Comme d’habitude, nous comparons la statistique obtenue à partir des données de l’échantillon à celle de la distribution du \(F\) selon les degrés de liberté et le seuil de signification spécifiés lorsque l’hypothèse nulle est vraie. Si la valeur du \(F\) observée est plus grande que celle déterminée par la distribution du \(F\), nous rejetterons l’hypothèse nulle.
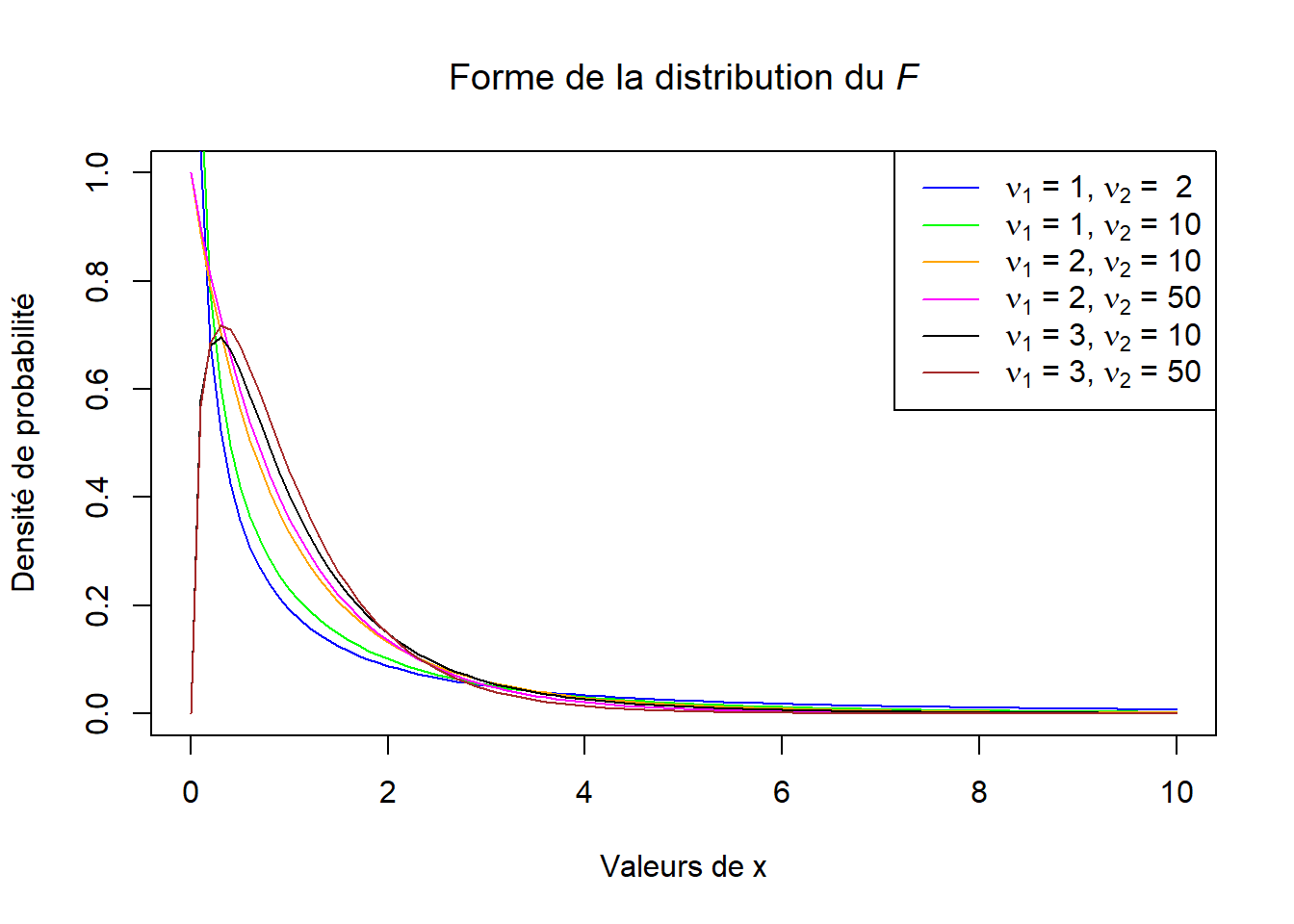
Figure 6.2: Distribution du \(F\) selon différentes valeurs de degrés de liberté.
6.1.2.3 Hypothèses statistiques
Comme nous l’avons vu dans les leçons précédentes, l’hypothèse nulle (bilatérale) avec le test \(t\) de Student sur deux groupes indépendants implique l’égalité des moyennes des deux groupes :
\(H_0\): \(\mu_{\mathrm{A}} = \mu_{\mathrm{B}}\) (non-différence)
\(H_a\): \(\mu_{\mathrm{A}} \neq \mu_{\mathrm{B}}\) (différence)
En ce qui a trait à l’ANOVA, l’hypothèse nulle a la même forme. Par exemple, pour un facteur qui compte quatre niveaux (p. ex., faible, modéré, élevé, très élevé), nous aurions l’hypothèse nulle suivante :
\(H_0\): \(\mu_{\mathrm{A}} = \mu_{\mathrm{B}}\) = \(\mu_{\mathrm{C}} = \mu_{\mathrm{D}}\) (non-différence)
\(H_a\): au moins une moyenne diffère des autres moyennes
Reprenons notre exemple sur la concentration d’ozone dans les trois jardins d’une ville industrielle. Nous pouvons émettre les hypothèses statistiques suivantes :
\(H_0\): \(\mu_{\mathrm{jardin \: A}} = \mu_{\mathrm{jardin \: B}}\) = \(\mu_{\mathrm{jardin \: C}}\) (non-différence)
\(H_a\): au moins une moyenne diffère des autres moyennes
\(\alpha = 0.05\)
Puisque nous avons déja calculé les sommes des carrés dans l’exemple 6.2, nous pouvons construire le tableau d’ANOVA qui nous permettra de tester l’hypothèse nulle (Table 6.2).
| Source |
Somme des carrés (\(SS\)) |
Degrés de liberté (\(df\)) |
Carré moyen (\(CM\)) |
ratio \(F\) |
|---|---|---|---|---|
| Jardin | 32.43 | 2 | 16.22 | 0.28 |
| Residuals | 2451.45 | 42 | 58.37 |
On constate que le ratio \(F\) est de 0.28 (\(16.22/58.37\)). Étant donné que \(P(F_{2, 42} \geq 0.28) = 0.7588\)18, on ne rejette pas \(H_0\) et on conclut que les moyennes des groupes ne diffèrent pas les unes des autres. La fonction aov( ) permet de réaliser une ANOVA dans R lorsque chaque groupe contient le même nombre d’observations19.
On peut constater que la variable Jardin est une variable caractère (chr). Celle-ci doit être un facteur afin de réaliser l’ANOVA. La transformation est réalisée à l’aide de la commande suivante :
La commande ci-dessous permet de valider que la variable Jardin est maintenant un facteur (factor).
## 'data.frame': 45 obs. of 2 variables:
## $ Ozone : num 14.82 20.59 6.18 7.61 31.35 ...
## $ Jardin: Factor w/ 3 levels "A","B","C": 1 1 1 1 1 1 1 1 1 1 ...On peut maintenant réaliser l’ANOVA et l’extraire à l’aide de la fonction summary( ). Cette dernière fonction est souvent utilisée pour obtenir un résumé des résultats d’une analyse statistique.
##exécuter l'ANOVA
aov1 <- aov(Ozone ~ Jardin, data = ozone)
##on extrait les résultats
summary(aov1)## Df Sum Sq Mean Sq F value Pr(>F)
## Jardin 2 32.4 16.22 0.278 0.759
## Residuals 42 2451.5 58.376.1.2.4 Suppositions
L’analyse de variance est une extension du test \(t\) de Student lorsqu’on souhaite comparer les moyennes entre plus de deux groupes. Il n’est donc pas surprenant que l’analyse de variance doive répondre aux mêmes conditions d’utilisation que le test \(t\). Pour effectuer l’ANOVA, les erreurs doivent être indépendantes. L’échantillonnage aléatoire et l’utilisation d’un bon dispositif expérimental aident à respecter cette condition. L’ANOVA requiert également que les variances des groupes soient égales (homoscédasticité): \(\sigma_1^2 = \sigma_2^2 = \sigma_3^2 \ldots \sigma_k^2\). Finalement, on suppose que chacun des groupes est issu d’une population normale (c.-à-d., résidus ou erreurs sont distribués normalement). Autrement dit, afin de pouvoir comparer des groupes dont la moyenne peut potentiellement différer d’un groupe à l’autre, il faut que ces groupes aient la même variance. Cette variance commune est estimée par le carré moyen de l’erreur (residual mean square, error mean square).
6.1.2.4.1 Résidus
À l’instar du test \(t\), nous utilisons les résidus pour diagnostiquer des problèmes liés à la normalité et à l’homogénéité des variances. Les résidus sont obtenus en calculant la différence entre les valeurs observées \(y_i\) et les valeurs qui sont prédites \(\hat{y}_i\) par notre modèle d’ANOVA. Dans le cas de l’ANOVA à un critère, les valeurs prédites (\(\hat{y}_i\)) correspondent à la moyenne arithmétique de chaque groupe. Nous obtenons les résidus à l’aide de \(y_i - \hat{y}_i\). Les fonctions residuals( ) et fitted( ) dans R permettent d’extraire les résidus et les valeurs prédites de plusieurs types d’analyses statistiques. Le prochain exemple illustre l’application directe de ces fonctions à l’objet qui contient le résultat de l’ANOVA.
On peut vérifier les suppositions de l’ANOVA que nous avons exécutée dans l’exemple précédent. On obtient les résidus en calculant la différence entre les valeurs observées et les valeurs prédites, \(y_i - \hat{y}_i\). On commence par extraire les valeurs observées et les valeurs prédites :
## [1] 14.82 20.59 6.18 7.61 31.35 11.62 32.70 26.18 19.91 10.96## 1 2 3 4 5 6 7 8 9 10
## 16.342 16.342 16.342 16.342 16.342 16.342 16.342 16.342 16.342 16.342## A B C
## 16.34200 18.20133 18.07800## 1 2 3 4 5 6 7 8 9 10
## -1.522 4.248 -10.162 -8.732 15.008 -4.722 16.358 9.838 3.568 -5.382##extraire résidus du modèle
res <- residuals(aov1)
res[1:10] #valeurs identiques au calcul obs - pred## 1 2 3 4 5 6 7 8 9 10
## -1.522 4.248 -10.162 -8.732 15.008 -4.722 16.358 9.838 3.568 -5.3826.1.2.4.2 Normalité des résidus et homogénéité de la variance
De la même façon qu’on utilise le graphique quantile-quantile lorsqu’on effectue un test \(t\), on utilise ce même graphique pour diagnostiquer des déviations par rapport à la supposition de normalité. La fonction qqnorm( ) permet d’obtenir ce graphique et la fonction qqline( ) ajoute une droite théorique représentant une distribution normale.
Pour évaluer l’homogénéité des variances des différents groupes, on peut utiliser le diagramme de boîtes et moustaches (boxplot( )) des résidus en fonction de chaque groupe. Un autre graphique utile pour diagnostiquer des problèmes de variances hétérogènes est le graphique des résidus en fonction des valeurs prédites. Ce dernier devrait montrer un patron nul, c’est-à-dire des points distribués uniformément de part et d’autre de 0 sur l’axe des \(y\) sans patron apparent (Figure 6.3a). L’hétérogénéité des variances se traduit parfois par l’apparition d’un patron en forme d’entonnoir, indiquant que les variances augmentent avec les valeurs prédites (Figure 6.3b). S’il y a des doutes par rapport au respect de ces conditions, plusieurs options sont possibles. Les transformations vues dans la leçon 4 de ce cours peuvent être utiles, ou encore des tests plus complexes qui ne nécessitent pas ces conditions.

Figure 6.3: Graphique de résidus en fonction des valeurs prédites illustrant l’homogénéité des variances (a) et l’hétérogénéité des variances (b). Notez le patron en forme d’entonnoir en b qui est indiqué par une variance qui augmente avec les valeurs prédites.
Nous poursuivons l’exemple 6.4 en vérifiant si la condition de normalité est respectée. Pour vérifier la normalité, on extrait les résidus de l’ANOVA et on examine le graphique quantile-quantile. On constate que la condition de normalité est assez bien respectée, quoiqu’il y ait quelques valeurs aux extrémités des queues qui dévient de la normalité (Figure 6.4a). Le graphique des résidus en fonction des valeurs prédites suggère que les variances sont plutôt homogènes, bien que le groupe avec la plus grande moyenne ait une variabilité légèrement plus faible que les autres (Figure 6.4b).
par(mfrow = c(1, 2))
##graphique quantile-quantile
qqnorm(res, ylab = "Quantiles observés",
xlab = "Quantiles théoriques",
main = "Graphique quantile-quantile",
cex.lab = 1.2)
##cex.lab indique que les étiquettes seront 1.2 fois plus grande
##ajout de droite théorique
qqline(res)
text(y = 15, x = -2, labels = "a")
##résidus vs valeurs prédites
plot(res ~ pred, ylab = "Résidus", xlab = "Valeurs prédites",
main = "Résidus vs valeurs prédites", cex.lab = 1.2)
text(y = 15, x = 16.5, labels = "b")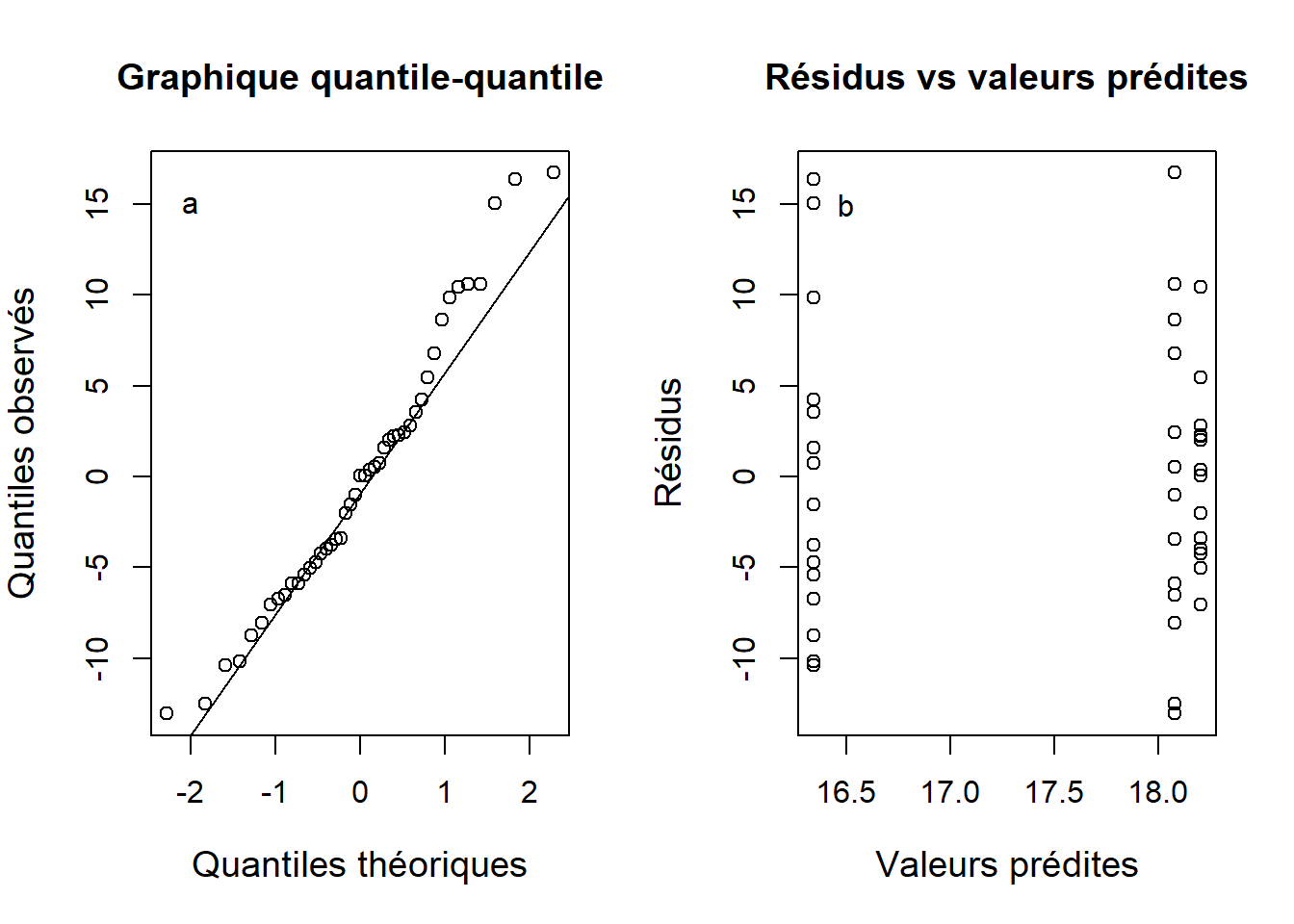
Figure 6.4: Graphique quantile-quantile des résidus de l’ANOVA sur les concentrations d’ozone (a) et résidus en fonction des valeurs prédites (b).
Nous avons maintenant toutes les notions en main afin de réaliser l’ANOVA et de vérifier le respect des conditions. C’est ce que nous ferons dans le prochain exemple.
On fait une étude de santé publique sur la consommation de boissons sucrées par les jeunes de 19 à 25 ans dans cinq régions de l’Est du Québec. Pour ce faire, on fait un sondage détaillé auprès de six jeunes par région et on estime pour chacun sa consommation annuelle en litres. Les cinq régions sont:
- Chaudière-Appalaches ();
- Côte-Nord ();
- Saguenay Lac-Saint-Jean ().
- Bas-Saint-Laurent ();
- Gaspésie-Iles–de-la-Madeleine ();
Les données sont incluses dans le jeu de données consommation.txt.
## Volume Region
## 1 55.1 CA
## 2 45.7 CA
## 3 45.0 CA
## 4 73.1 CA
## 5 49.9 CA
## 6 63.2 CANous avons les hypothèses statistiques suivantes :
\(H_0\): \(\mu_{\mathrm{SLSJ}} = \mu_{\mathrm{GIM}} = \mu_{\mathrm{CA}} = \mu_{\mathrm{CN}} = \mu_{\mathrm{BSL}}\) (non-différence)
\(H_a\): au moins une moyenne diffère parmi toutes les moyennes
\(\alpha = 0.05\)
Avant de faire l’analyse, on peut visualiser rapidement les données et la variabilité de chaque groupe avec boxplot( ) (Figure 6.5).
##boxplot de données brutes
boxplot(Volume ~ Region, data = cons,
ylab = "Volume",
xlab = "Régions")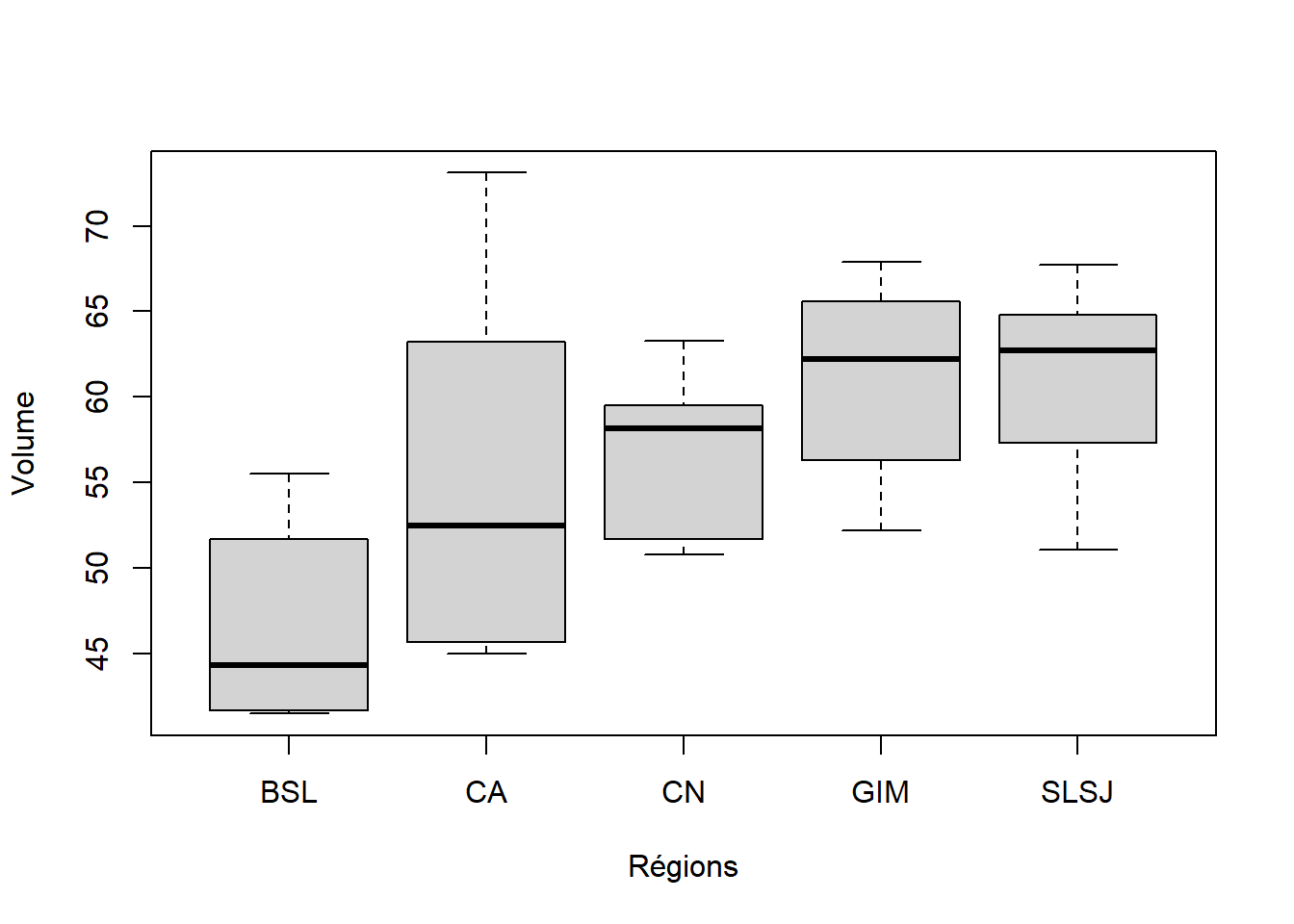
Figure 6.5: Diagramme de boîtes et moustaches de la consommation annuelle de volume de boissées sucrées par jeune dans 5 régions de l’Est du Québec.
On exécute l’ANOVA à un critère :
## Conversion en facteur de la variable Region
cons$Region <- as.factor(cons$Region)
##ANOVA
m1 <- aov(Volume ~ Region, data = cons)Avant de se lancer dans l’interprétation, il faut vérifier les suppositions de l’ANOVA, notamment celles concernant l’homoscédasticité et la normalité des résidus. On constate que la supposition d’homogénéité des variances est assez bien respectée et une seule observation se démarque des autres avec une valeur > 15 (Figure 6.6a}). Toutefois, il est important de noter que six observations par groupe est une taille d’échantillon faible pour vérifier cette supposition d’homoscédasticité. Le graphique quantile-quantile avec les résidus indique que la supposition de normalité est respectée pour ce jeu de données (Figure 6.6b).
##on organise la fenêtre graphique
##pour avoir 1 rangée et deux colonnes
##de graphiques
par(mfrow = c(1, 2))
##homoscédasticité
plot(residuals(m1) ~ fitted(m1),
ylab = "Résidus", xlab = "Valeurs prédites",
main = "Résidus vs valeurs prédites",
cex.lab = 1.2)
##normalité
qqnorm(residuals(m1), ylab = "Quantiles observés",
xlab = "Quantiles théoriques",
main = "Graphique quantile-quantile",
cex.lab = 1.2)
qqline(residuals(m1))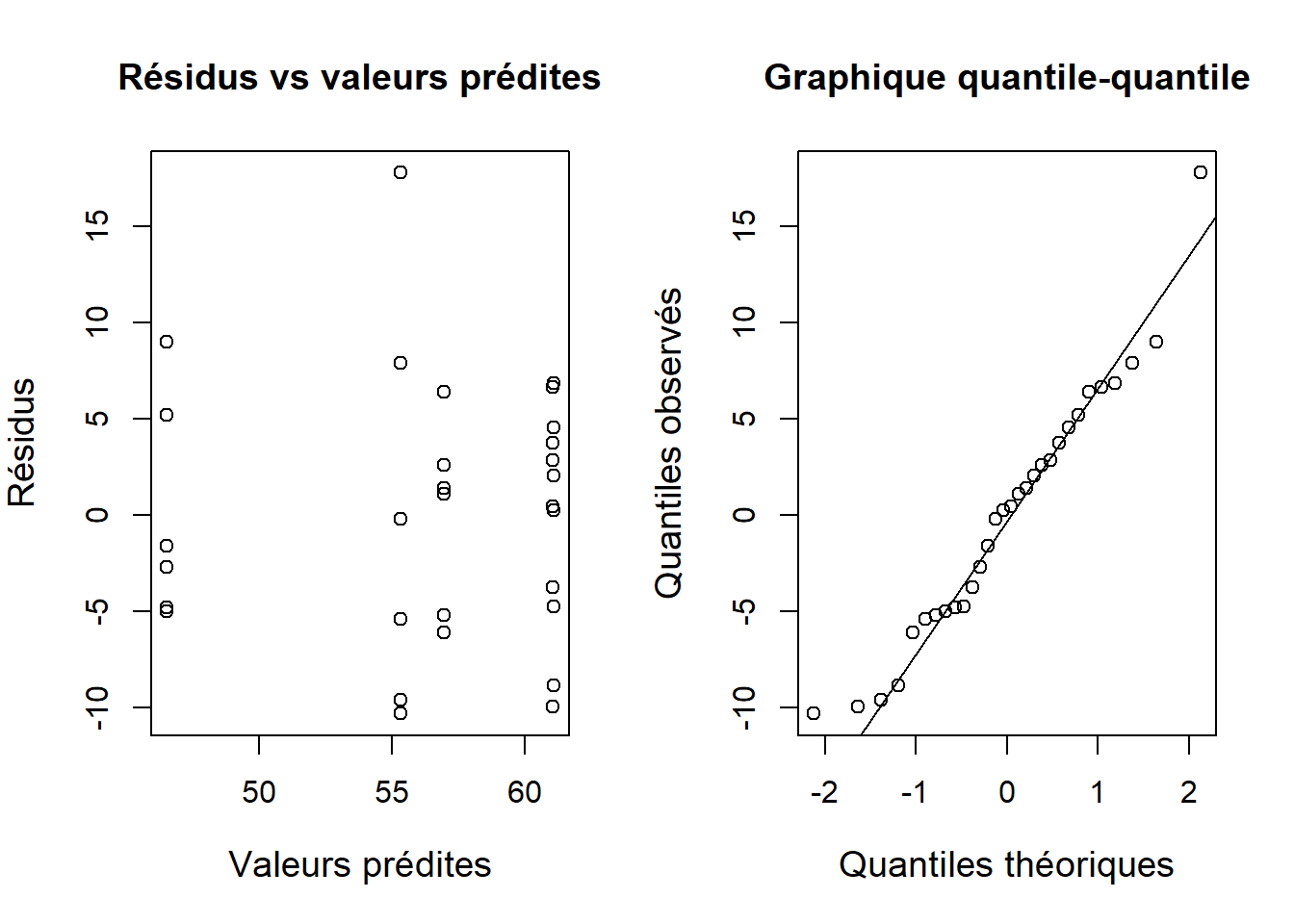
Figure 6.6: Diagnostics de l’ANOVA.
On peut procéder à l’interprétation des résultats.
## Df Sum Sq Mean Sq F value Pr(>F)
## Region 4 853.6 213.39 4.302 0.00875 **
## Residuals 25 1240.2 49.61
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1On note dans summary(m1) que la dernière ligne du tableau Signif. codes donne les symboles qui décrivent le seuil de signification statistique du facteur Region. Ces caractères ne sont affichés qu’en présence de termes significatifs dans l’analyse. Ici, Region a les caractères \(\mathtt{\ast\ast}\) sur sa ligne, indiquant que \(P \leq 0.01\). Ces symboles n’ont d’autre fonction que d’attirer l’attention de l’analyste sur les termes significatifs dans l’analyse. Il est peu probable d’observer une valeur de \(F\) de 4.3 dans une expérience avec des échantillons (groupes) qui ont la même taille que le jeu de données original tirés d’une population où \(H_0\) est vraie. La valeur exacte du \(P\) est de 0.0088 (\(P(F_{4, 25} \geq 4.3015) = 0.0088\)). On rejette l’hypothèse nulle et on conclut qu’il y a un effet de la région : au moins une moyenne d’une région diffère d’une autre. Toutefois, l’ANOVA ne nous permet pas d’identifier quelles régions diffèrent entre elles. Pour ce faire, on doit utiliser un autre type de test qui sera présenté dans la prochaine section.
6.1.3 Comparaison multiples
L’ANOVA permet de déterminer si la variance expliquée par le facteur à l’étude est supérieure à la variance résiduelle (c.-à-d., la variance inexpliquée). Ainsi, le tableau d’ANOVA nous permet de rejeter ou non \(H_0\). Lorsqu’on rejette l’hypothèse nulle après avoir effectué un test \(t\) pour comparer deux groupes indépendants, on sait qu’il existe une différence entre ces deux groupes. Dans une ANOVA qui a plus de deux groupes, le rejet de \(H_0\) ne nous révèle pas où se trouvent les différences20. Les comparaisons multiples permettent d’identifier les différences entre les moyennes des groupes.
Comme nous l’avons mentionné au début de ce texte, effectuer des comparaisons multiples augmente la probabilité de commettre une erreur de type I. L’ANOVA est conçue pour comparer tous les groupes simultanément afin d’évaluer l’effet global du traitement. Lorsque l’ANOVA entraîne le rejet de l’hypothèse nulle, il s’avère nécessaire d’exécuter des comparaisons multiples entre les groupes afin de trouver quelles sont les différences. Ces comparaisons effectuées après l’ANOVA augmentent aussi la probabilité de commettre une erreur de type I – la probabilité de commettre ce type d’erreur est supérieure au seuil \(\alpha\) que nous avons fixé. Puisque les comparaisons multiples sont effectués après l’ANOVA, on parle souvent de tests a posteriori ou post hoc (post hoc tests, a posteriori tests).
6.1.3.1 Erreurs associées aux comparaisons multiples
On peut commettre des erreurs à deux niveaux lorsqu’on fait des comparaisons multiples : une erreur au niveau de la comparaison (comparison-wise error) et une erreur au niveau de l’expérience (experiment-wise error). L’erreur au niveau de la comparaison se traduit par la déclaration d’un faux positif lors d’une comparaison spécifique entre deux groupes. La probabilité de commettre cette erreur pour une comparaison donnée est déterminée par \(\alpha\). L’erreur au niveau de l’expérience, quant à elle, correspond à déclarer au moins un faux positif parmi toutes les comparaisons effectuées. Plus on a de groupes (et de comparaisons), plus notre erreur au niveau de l’expérience augmente. Le prochain exemple illustre les différences entre les deux niveaux d’erreur.
Pour faciliter la compréhension de l’erreur liée à la comparaison entre les groupes et l’erreur liée à l’expérimentation, nous vous proposons l’exercice de simulation suivant. Nous simulons des données où l’hypothèse nulle est vraie, c’est-à-dire qu’il n’y a aucune différence entre les moyennes des groupes. On crée trois groupes de \(n = 50\) tirés d’une population suivant une distribution normale avec \(\mu = 5\) et \(\sigma = 3\) (c.-à-d., N(5, 3)). En d’autres mots, nous simulons les données de trois groupes et ces données sont toutes tirées de la même population pour satisfaire \(H_0\). Il y a trois comparaisons possibles: groupe 1 vs groupe 3, groupe 2 vs groupe 3 et groupe 1 vs groupe 2. Nous voulons savoir quelle est la probabilité de commettre une erreur liée à la comparaison et une erreur liée à l’expérience. On peut décrire l’algorithme de la simulation comme suit :
- on génère des données aléatoires pour chacun des groupes conformément à \(H_0\) (
rnorm(n = 50, mean = 5, sd = 3)); - on réalise les trois comparaisons (1 vs 3, 2 vs 3, 1 vs 2) à l’aide de trois tests \(t\) (
t.test( )); - on détermine pour chaque test \(t\) effectué, si \(P \leq \alpha\) (p. ex., \(P \leq 0.05\));
- on répète les étapes 1 à 3 un grand nombre de fois (p. ex., 1000 fois).
On peut réaliser ce genre d’exercice avec des boucles dans R. La section Les boucles avec R couvre les concepts de base et donne des exemples pour construire des boucles qui permettront de réaliser des tâches répétitives.
À la fin de la simulation, nous pouvons constater le nombre de fois où nous avons rejeté \(H_0\) par erreur. Ici, nous savons que \(H_0\) est vraie puisque nous avons simulé des données qui respectent l’hypothèse nulle (aucune différence entre les moyennes des groupes). À chaque fois que nous avons rejeté \(H_0\) dans cette simulation, nous avons commis une erreur.
Le tableau 6.3 montre le résultat des 10 premières itérations de la simulation (les étapes 1 à 3 ci-dessus). Les trois premières colonnes correspondent aux trois comparaisons possibles. La valeur NS correspond à un résultat non significatif (\(H_0\) non rejetée). Le symbole * indique le rejet de \(H_0\) et, par conséquent, une erreur liée à la comparaison. La quatrième colonne correspond à l’erreur liée à l’expérience. Cette colonne prend la valeur de 1 lorsqu’au moins une comparaison a rejeté \(H_0\) (une erreur liée à l’expérience) et la valeur de 0 lorsqu’aucune comparaison ne rejette \(H_0\).
| 1 vs 2 | 1 vs 3 | 2 vs 3 | Erreur liée à l’expérience |
|---|---|---|---|
| NS | NS | NS | 0 |
| NS | NS | NS | 0 |
| NS | NS | NS | 0 |
| NS | NS | NS | 0 |
| NS | NS | NS | 0 |
| NS | NS | NS | 0 |
| NS | NS | NS | 0 |
| NS | * | * | 1 |
| NS | NS | NS | 0 |
| NS | * | NS | 1 |
La première rangée du tableau 6.3 correspond à la première itération, et on constate qu’aucune erreur de comparaison n’a été commise, et, par conséquent, aucune erreur liée à l’expérience. La huitième rangée du même tableau montre que les comparaisons 1 vs 3 et 2 vs 3 ont rejeté par erreur \(H_0\) (erreurs liées à la comparaison) et qu’il y a donc une erreur au niveau de l’expérience. On remarquera qu’à l’intérieur de chaque colonne, la proportion du nombre d’erreurs de comparaison par rapport au nombre total d’itérations oscille autour de \(\alpha = 0.05\), puisque c’est le seuil que nous avons utilisé dans les comparaisons multiples. Toutefois, en compilant le nombre total d’erreurs au niveau de l’expérience (la quatrième colonne), on obtient la probabilité de commettre une erreur au niveau de l’expérience. Ici, nous avons :
\[\frac{124 \: \mathrm{erreurs \: li\acute{e}es \: \grave{a} \: l^\prime exp\acute{e}rience}}{1000 \: \mathrm{it\acute{e}rations}} = 0.124\]
Bien que nous ayons fixé le seuil \(\alpha\) à 0.05, la probabilité de commettre une erreur au niveau de l’expérience est supérieure à ce seuil (0.124). Ce problème a motivé le développement de plusieurs types de comparaisons multiples afin de contrôler l’erreur au niveau de l’expérience.
6.1.3.2 Suppositions
Les tests de comparaisons multiples ont les mêmes suppositions de normalité et d’homoscédasticité que l’ANOVA. Les comparaisons multiples sont moins robustes face aux déviations de ces conditions, surtout à celles d’homoscédasticité, qui augmentent les erreurs de type I et II.
6.1.3.3 Structure générale
Un grand nombre de tests de comparaisons multiples ont été développés pour différentes applications. En général, les tests de comparaisons multiples suivent le même principe:
- on effectue l’ANOVA;
- si on rejette \(H_0\), on peut faire des comparaisons multiples. Si on ne rejette pas \(H_0\), l’analyse est terminée. Ce choix de ne pas poursuivre avec des comparaisons multiples s’explique du fait que l’ANOVA est plus puissante que les comparaisons multiples;
- on classe les moyennes des groupes par ordre croissant;
- on calcule la différence entre la plus grande moyenne vs la plus petite;
- comme pour un test \(t\) (voir la leçon 4), on divise les différences par une erreur-type pour une statistique \(q\), c-à-d un quantile de la distribution associée à l’hypothèse nulle: \(q = (\bar{x}_{grande} - \bar{x}_{petite})/SE\) . Le calcul du quantile \(q\) implique donc le carré moyen des erreurs, \(MSE\) (\(MSE\) étant une fonction de \(SE\)), mais dépend du test et de sa distribution;
- on compare le \(q_{obs}\) à un \(q_{th\acute{e}orique}\), qui dépend du seuil \(\alpha\), des \(df\) du \(MSE\) et du nombre de groupes comparés. Dans la plupart des cas, \(\alpha\) représente l’erreur au niveau de l’expérience;
- un \(q_{obs} \geq q_{th\acute{e}orique}\) indique qu’il y a une différence entre la paire de moyennes comparées.
Habituellement, on commence en comparant la plus grande moyenne \(\bar{x}_{k}\) des \(k\) groupes (ordonnés en ordre croissant de 1 à \(k\)) aux autres (vs \(\bar{x}_{1}\), vs \(\bar{x}_{2}\), , vs \(\bar{x}_{k - 1}\)). Si, par exemple, on ne rejette plus \(H_0\) à partir de la comparaison de \(\bar{x}_{k}\) vs \(\bar{x}_{2}\), il n’est pas nécessaire de vérifier les comparaisons pour les moyennes de 3 à \(k-1\) parce que l’on sait déjà qu’on ne rejettera pas \(H_0\). On passe ensuite à la comparaison de \(\bar{x}_{k - 1}\) avec les moyennes de 1 à \(k-2\). Encore une fois, nous pouvons arrêter les comparaisons avec les moyennes subséquentes, dès qu’on ne rejettera plus \(H_0\) pour l’une des moyennes. On procède ainsi pour toutes les moyennes pour, enfin, terminer en comparant \(\bar{x}_{2}\) vs \(\bar{x}_{1}\). Par exemple, considérons les moyennes de cinq groupes organisées par ordre croissant :
\[ \begin{array}{l c c c c c} A & \quad C & \quad B & \quad E & \quad D \\ 3.1 & \quad 9.3 & \quad 10.5 & \quad 10.9 & \quad 11.8 \end{array} \]
Si on compare la plus grande moyenne (groupe D) au groupe C et que l’on ne rejette pas \(H_0\), on ne testera ni le groupe D vs le groupe B, ni le groupe D vs le groupe E. De plus, on ne testera pas le groupe E vs le groupe C, car les groupes D et C ne diffèrent pas l’un de l’autre, et la valeur de E est comprise entre celles de C et D.
6.1.3.4 Test de Tukey
Parmi les tests de comparaisons multiples, mentionnons le test de Dunnett (lorsqu’on veut comparer tous les groupes à un témoin), le test de Student-Newman-Keuls (SNK, Newman-Keuls) qui dépend du nombre de moyennes séparant les moyennes comparées, le test de Scheffé, et le test de Tukey (Tukey test, Tukey’s Honestly Significant Difference (HSD) test). Le test de Tukey est d’ailleurs l’un des tests de comparaisons multiples les plus recommandés. La statistique \(q\) s’obtient comme suit :
\[ q_{obs} = \frac{\bar{x}_{groupe \: 1} - \bar{x}_{groupe \: 2}}{SE}\]
où \(\bar{x}_{groupe \: 1}\) correspond à la moyenne du groupe 1, \(\bar{x}_{groupe \: 2}\) à la moyenne du groupe 2 et \(SE\) est l’erreur-type du test de Tukey. Cette dernière est donnée par \(SE = \sqrt{\frac{MSE}{n}}\), où \(MSE\) est le carré moyen des erreurs et \(n\) est le nombre d’observations dans chaque groupe. Nous appliquons le test de Tukey dans le prochain exemple.
Dans l’exemple 6.6, nous avons rejeté l’hypothèse nulle à l’aide de l’ANOVA réalisée sur des données de consommation annuelle de boissons sucrées par des jeunes de 5 régions différentes. On peut appliquer le test de Tukey pour trouver où se trouvent les différences entre les moyennes des groupes. On peut commencer par calculer les moyennes des groupes et les ordonner :
##moyennes des groupes
moy <- tapply(X = cons$Volume, INDEX = cons$Region, FUN = mean)
##en ordre croissant et en arrondissant à deux décimales
round(sort(moy), digits = 2)## BSL CA CN SLSJ GIM
## 46.52 55.33 56.93 61.05 61.07Nous pouvons calculer l’erreur-type du dénominateur nécessaire au calcul de la statistique, \(SE = \sqrt{\frac{MSE}{n}}\) :
##sous-jeu de données
SLSJ <- cons[cons$Region == "SLSJ", ]
GIM <- cons[cons$Region == "GIM", ]
CA <- cons[cons$Region == "CA", ]
CN <- cons[cons$Region == "CN", ]
BSL <- cons[cons$Region == "BSL", ]
##SSE de SLSJ
SSE.SLSJ <- sum((SLSJ$Volume-mean(SLSJ$Volume))^2)
##SSE de GIM
SSE.GIM <- sum((GIM$Volume-mean(GIM$Volume))^2)
##SSE de CA
SSE.CA <- sum((CA$Volume-mean(CA$Volume))^2)
##SSE de CN
SSE.CN <- sum((CN$Volume-mean(CN$Volume))^2)
##SSE de BSL
SSE.BSL <- sum((BSL$Volume-mean(BSL$Volume))^2)
##SSE
SSE <- SSE.SLSJ + SSE.GIM + SSE.CA + SSE.CN + SSE.BSL
SSE## [1] 1240.203## [1] 25## [1] 49.60813## [1] 2.875417Par la suite, on calcule le \(q\) pour chaque comparaison multiple (tableau 6.4). Chaque valeur de \(q\) est comparée à ce qu’on devrait obtenir si \(H_0\) est vraie et la fonction ptukey( ) nous fournit la probabilité cumulative en faveur de \(H_0\) pour nmeans groupes et df degrés de liberté du terme d’erreur de l’ANOVA. À titre d’exemple, la probabilité de la comparison GIM vs BSL se calcule à l’aide de la commande suivante :
## [1] 0.01152797Où \(q\) est \(q_{obs} = (\bar{x}_{GIM} - \bar{x}_{BSL})/{SE}\)
Comme d’habitude, on rejette \(H_0\) lorsqu’elle est peu probable (c-à-d, \(P \leq \alpha\)).
| Comparaison | Difference | SE | q_obs | P | Conclusion |
|---|---|---|---|---|---|
| GIM vs BSL | 14.55 | 2.88 | 5.06 | 0.012 | rejeter \(H_0\) |
| GIM vs CA | 5.73 | 2.88 | 1.994 | 0.627 | ne pas rejeter \(H_0\) |
| GIM vs CN | 4.13 | 2.88 | on ne teste pas | ||
| GIM vs SLJS | 0.02 | 2.88 | on ne teste pas | ||
| SLSJ vs BSL | 14.53 | 2.88 | 5.054 | 0.012 | rejeter \(H_0\) |
| SLSJ vs CA | 5.72 | 2.88 | on ne teste pas | ||
| SLSJ vs CN | 4.12 | 2.88 | on ne teste pas | ||
| CN vs BSL | 10.42 | 2.88 | 3.623 | 0.109 | ne pas rejeter \(H_0\) |
| CN vs CA | 1.6 | 2.88 | on ne teste pas | ||
| CA vs BSL | 8.82 | 2.88 | on ne teste pas |
On peut créer ce tableau rapidement à l’aide de la fonction TukeyHSD( ) :
## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = Volume ~ Region, data = cons)
##
## $Region
## diff lwr upr p adj
## CA-BSL 8.81666667 -3.125984 20.75932 0.2243248
## CN-BSL 10.41666667 -1.525984 22.35932 0.1088202
## GIM-BSL 14.55000000 2.607350 26.49265 0.0115253
## SLSJ-BSL 14.53333333 2.590683 26.47598 0.0116387
## CN-CA 1.60000000 -10.342650 13.54265 0.9946026
## GIM-CA 5.73333333 -6.209317 17.67598 0.6272414
## SLSJ-CA 5.71666667 -6.225984 17.65932 0.6297485
## GIM-CN 4.13333333 -7.809317 16.07598 0.8453941
## SLSJ-CN 4.11666667 -7.825984 16.05932 0.8472695
## SLSJ-GIM -0.01666667 -11.959317 11.92598 1.0000000D’après la sortie R, on observe seulement deux différences significatives (\(\alpha= 0.05\)) : la consommation moyenne pour la région BSL est plus petite que celles des régions SLSJ et GIM. En conséquence, on ne peut pas conclure que les moyennes pour les régions CA et CN diffèrent avec celles des autres régions, ni que la moyenne pour la région SLSJ diffère de celle de la région GIM.
6.1.3.5 Présentation des résultats
Il est possible de présenter les résultats des comparaisons multiples de différentes manières. L’une d’elles consiste à ordonner les groupes selon la valeur des moyennes et d’unir à l’aide d’un trait les groupes qui ne diffèrent pas entre eux. On peut aussi présenter les résultats graphiquement, typiquement en présentant les moyennes ± des barres d’erreur. Comme barre d’erreur, on peut utiliser l’erreur-type des moyennes de chaque groupe, la racine-carrée du carré moyen des erreurs (\(\sqrt{MSE}\)) ou des intervalles de confiance construits à partir de l’une ou l’autres des mesures de dispersion mentionnées. On emploie des lettres pour distinguer les groupes qui diffèrent entre eux sur le graphique. Le prochain exemple illustre ces deux méthodes avec les données de consommation annuelle de boissons sucrées par des jeunes selon différentes régions de l’Est du Québec. À noter que les comparaisons multiples indiquent parfois qu’un traitement appartient à deux groupes. Cette double appartenance indique que la comparaison multiple n’a pas permis de détecter une différence entre ces deux groupes.
Les tests de comparaisons multiples ne peuvent parfois trouver de groupes qui diffèrent entre eux, alors que l’ANOVA avait rejeté \(H_0\). L’ANOVA est plus puissante que les tests de comparaisons multiples, ce qui explique, à l’occasion, l’absence d’une différence entre les paires de groupes. Puisque l’ANOVA est plus puissante que les comparaisons multiples, nous recommandons de ne pas procéder à des comparaisons multiples si l’ANOVA n’a pas réussi à rejeter \(H_0\).
On peut représenter succinctement le résultat des comparaisons multiples sur les données de consommation de boissons sucrées selon la région :
| BSL | CA | CN | SLSJ | GIM |
|---|---|---|---|---|
| 46.52 | 55.33 | 56.93 | 61.05 | 61.07 |
La présentation des résultats à l’aide de traits facilite l’interprétation. On voit rapidement que CA et CN ont une double appartenance: ils appartiennent au groupe constitué de BSL, CA et CN ainsi qu’au groupe composé de CA, CN, SLSJ et GIM. Les groupes SLSJ et GIM ne diffèrent pas entre eux, mais sont différents du groupe BSL. En effet, le même trait relie les groupes SLSJ et GIM et ce même trait n’inclut pas le groupe BSL. Le graphique montre la même information (présence de deux groupes), mais à l’aide de lettres (Figure 6.7). On remarque que les groupes CA et CN ont une double appartenance puisqu’ils sont identifiés avec deux lettres. On trouve le code complet pour obtenir le graphique ci-dessous :
##ordonner moyennes
moys <- sort(moy)
##calculer racine carrée de MSE
sqrt.MSE <- sqrt(MSE)
##calculer les limites des barres d'erreur
lim.sup <- moys + sqrt.MSE
lim.inf <- moys - sqrt.MSE
##créer graphique vide sans axe des x's
plot(x = 0, y = 0, type = "n",
ylim = c(min(lim.inf), max(lim.sup+10)),
xlim = c(0, 6), xlab = "Région",
ylab = "Consommation annuelle (L)",
main = "Moyennes ± racine-carrée de MSE",
xaxt = "n", cex.lab = 1.2)
##ajouter axe des x's
axis(side = 1, at = c(1, 2, 3, 4, 5),
labels = names(moys))
##ajouter moyennes
points(x = c(1, 2, 3, 4, 5),
y = moys)
##ajouter barres d'erreurs
arrows(x0 = c(1, 2, 3, 4, 5),
y0 = lim.inf,
x1 = c(1, 2, 3, 4, 5),
y1 = lim.sup, length = 0.05,
angle = 90, code = 3)
##ajouter les lettres, lim.sup + 10
text(x = 1, y = 54.5, labels = "a")
text(x = 2, y = 63.3, labels = "ab")
text(x = 3, y = 64.9, labels = "ab")
text(x = 4, y = 69.0, labels = "b")
text(x = 5, y = 69.1, labels = "b")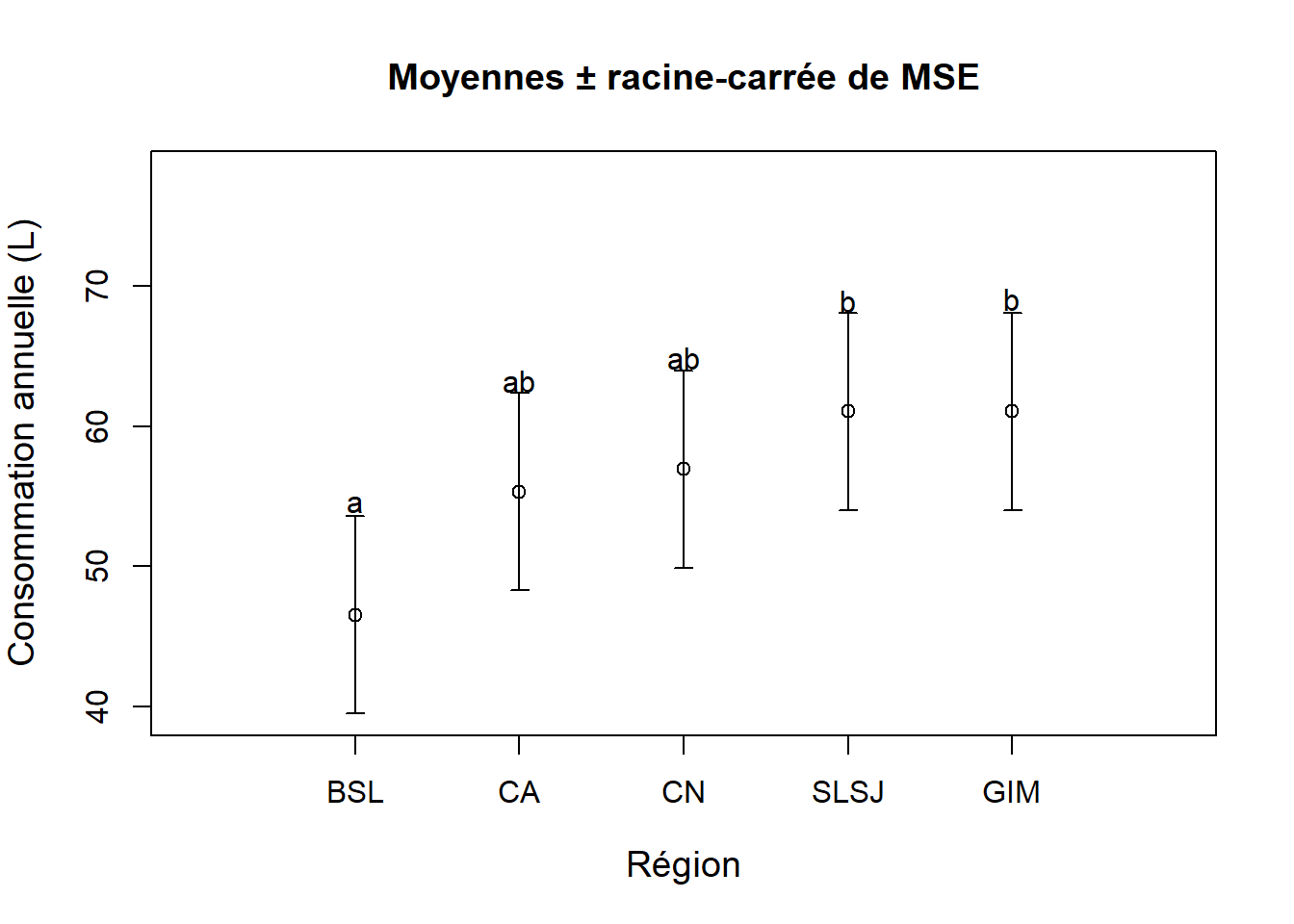
Figure 6.7: Présentation graphique des résultats des comparaisons multiples avec le test de Tukey.
6.1.4 Conclusion
Nous venons d’étudier le concept de comparaisons multiples ainsi que les problèmes qui y sont associés, notamment une augmentation de la probabilité de commettre une erreur de type I (déclarer un faux positif). Au lieu d’utiliser une série de tests \(t\), nous avons vu que l’analyse de variance (ANOVA) permet de comparer tous les groupes simultanément en estimant la variance expliquée par le facteur (variable catégorique) d’intérêt et en la comparant à la variance résiduelle (inexpliquée). Le tableau d’ANOVA véhicule beaucoup d’information et il est important d’inclure ses détails dans la rédaction des résultats. Bien que l’ANOVA permette de déterminer si le facteur a un effet important sur la variable réponse, elle ne permet pas de déterminer où se trouvent les différences. Pour ce faire, nous avons recours à des tests de comparaisons multiples exécutés a posteriori qui contrôlent l’erreur au niveau de l’expérience. Pour terminer, nous avons fait quelques propositions concernant la présentation des résultats afin de faciliter l’interprétation d’une ANOVA.
Rappel: Ici, la valeur de \(P\) correspond à la probabilité d’obtenir une valeur de \(F\) supérieure ou égale à celle qu’on a observée (dans les données originales) lorsqu’on répète l’échantillonnage avec la même taille d’échantillon dans la même population et que l’hypothèse nulle est vraie. On peut écrire plus succinctement: \(P = 0.7588\).↩︎
Dans les cas où le nombre d’observations varie d’un groupe à l’autre, il est préférable d’utiliser la fonction plus générale,
lm( )qui permet de réaliser plusieurs types de modèles linéaires.↩︎Le tableau d’ANOVA classique ne permet pas de décortiquer où se trouvent les différences entre les groupes. Néanmoins, il est possible d’utiliser des contrastes orthogonaux pour décomposer la somme des carrés du facteur à l’intérieur du tableau d’ANOVA. Ce concept est plus avancé et ne sera pas couvert dans le cours.↩︎